So the CDH Cluster was replaced by HDP Cluster and everything was going smooth for time being. Until the time when I started getting a dead RegionServer. Frequently. So a deep dive was needed to dig out what indeed was happening. And it turned out to be a long dive.
The following was the logline:
2017-05-23 06:59:22,173 FATAL [regionserver/<hostname>/10.10.205.55:16020] regionserver.HRegionServer: ABORTING region server <hostname>,16020,1493962926376: org.apache.hadoop.hbase.YouAreDeadException: Server REPORT rejected; currently processing<hostname>,16020,1493962926376 as dead server
This alone did not tell much. Further scrolling up in logs, I found this:
2017-05-24 04:55:34,712 INFO [RS_OPEN_REGION-hdps01:16020-2-SendThread(<zkhost>:2181)] zookeeper.ClientCnxn: Client session timed out, have not heard from server in 31947ms for sessionid 0x15be7e4d09e1c4c, closing socket connection and attempting reconnect
2017-05-24 04:55:34,713 WARN [regionserver/<rs-host>/10.10.205.55:16020] util.Sleeper: We slept 16865ms instead of 3000ms, this is likely due to a long garbage collecting pause and it's usually bad, see //hbase.apache.org/book.html#trouble.rs.runtime.zkexpired
2017-05-24 04:55:34,718 WARN [JvmPauseMonitor] util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 15598ms
1434184 No GCs detected
So according to these lines, something paused the JVM and it was not able to send hart-beat to zookeeper. The node there in zookeeper expired and the HBase Master marked it as dead regionserver. They also have given a link in log line which points out to a solution. Go ahead and have a look at it. So basically it says these could be the reasons behind:
- Not enough RAM while running large imports.
- Swap partition enabled
- Something hogging the CPU
- Low ZooKeeper timeout.
So first three options were ruled out for my dead regionserver. What I had to do was increase zookeeper timeout. BUT! I already had set the zookeeper session timeout (zookeeper.session.timeout) to 30min. And dead regionserver appeared only after 30sec or so.
As suggested in link above, I tried to set tickTime value (hbase.zookeeper.property.tickTime) to 6s. The calculation is something like this:
Min timeout = 2 * tickTime
Max timeout = 20 * tickTime
So here it must be 120 sec as a zookeeper timeout. But still timeouts were occurring about 40s after.I pulled up GC longs, there was no such long GC. So I went in and checked zookeeper config. Zookeeper also had tickTime value. Confusing it was and now I was not sure which tickTime was be applicable to the dead regionserver. There were two different values of ticktime. One in ZK and one in HBase.
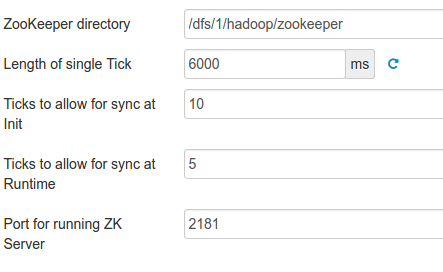
As confusing as it was, I went to check zookeeper logs. There I found the cause; the sessions negotiated with zookeeper from dead regionserver were of 40s (20*2s of original ticktime) So clearly the timeout and ticktime we set in regionserver on hbase side were not taking effect. Strange! Roaming around in HDP Server’s UI, I found this glorious piece of help-text. (Could not take a screenshot as that pop-up appeared only when I hover 😛 )
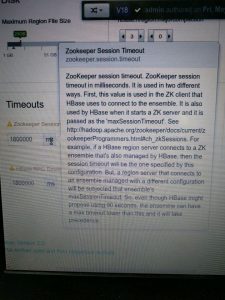
Now it was evident that if you are using different set of zookeeper quorum, the value set in hbase wont affect! **What? Why do you not print this in bold on some heading?? **So this was the cause and the ticktime was needed to set in zookeeper (as done already: see the screenshot ^^). Many times GC cause long delays. Apart from increasing timeout, you may also want to tune your GC. Also you may want to look into Tuning Your HBase or maybe benchmark it.
After increasing tickTime in zookeeper, it’s running fine and it’s been two days. Let’s hope it just stays that way 🙂