I was reading on HDFS (Hadoop’s distributed file system) and it’s internals. How does it store data. What is reading path. What is writing path. How does replication works. And to understand it better my mentor suggested me to implement the same. And so I made PyDFS. (Screenshots at bottom of the post)
So the choice of my language was python of course as it has vast number of modules available and you can code faster. I tried to implement very basic distributed file system and the code is ~200 lines. Before I started coding, some decisions needed to be taken.
Update:
I gave a talk at SRECon 2019 on the same subject, if you prefer detailed explanation in video format, checkout SRECon19 Asia: Let’s Build a Distributed File System or just scroll down to the bottom of the page.
Architecture:
Because it is a HDFS clone. It also has similar architecture. The naming for components are inspired from SaltStack. It has a Master(NameNode) and a Minion(DataNode). And a client to communicate with file system.
Master will store file system namespace: Files,blocks,file to block mapping,block to minion mapping.
Minion will just store the blocks. And upon request read or write operations on blocks.
For communication between components, I first thought of exposing HTTP API. So that every component will listen on a port and calls can be made on HTTP as implementing the same would have been fairly easy using Flask. But as mentioned in HDFS architecture, it uses custom RPC protocol for communication over TCP, I searched for something similar for Python and found RPyC. RPyC is very simple and easy to use.
How does this distributed file system work?
Because I was trying to clone HDFS, I tried to follow similar read and write patterns.
- To write a file, master will allocate blocks and a minion on which it will be stored. Client will write it to one minion and that minion will pass data to next one.
- For reading master will provide list of blocks and its location and client will read sequentially. If reading fails from one minion, it will try next minion.
- File system persistence is implemented via pickling the object. When you give Ctrl+C to master, it will dump the matadata to a file and it will load the same when you fire master up.
Implementation:
I have uploaded the code on GitHub under sanketplus/PyDFS. I made this during a weekend and I have not added comments but I think code is fairly understandable. Feel free to Star it or make a PR 🙂
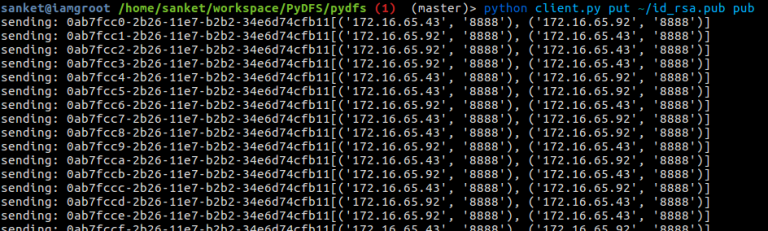
Here’s couple of screenshots of PyDFS in action:
In first image we are putting a file into DFS (my public key) and the lines you see are the blocks of the file (I have set smaller block size here). In second image we are trying to get the image from DFS and it will print it on stdout.